django网站搭建
–关于我最近在干嘛–
零基础开始的一个独立bootstrap+django网站搭建学习
需求:增删改查+上传下载文件+导出数据到csv+筛选+搜索
项目完整代码:https://github.com/0xkami/django-web
0x1 基础功能
利用pycharm搭建一个django项目,可以成功开启最基础的访问
前端使用bootstrap,模版使用的是clearmin,很简洁的一个管理平台
0x11 整体框架:
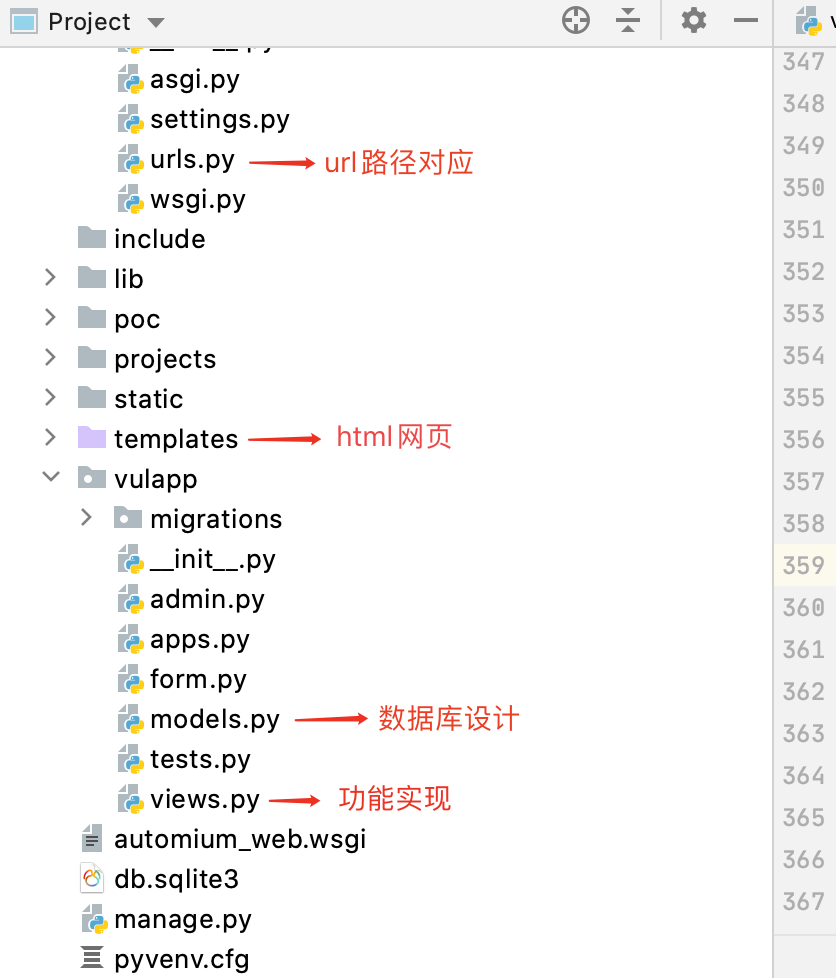
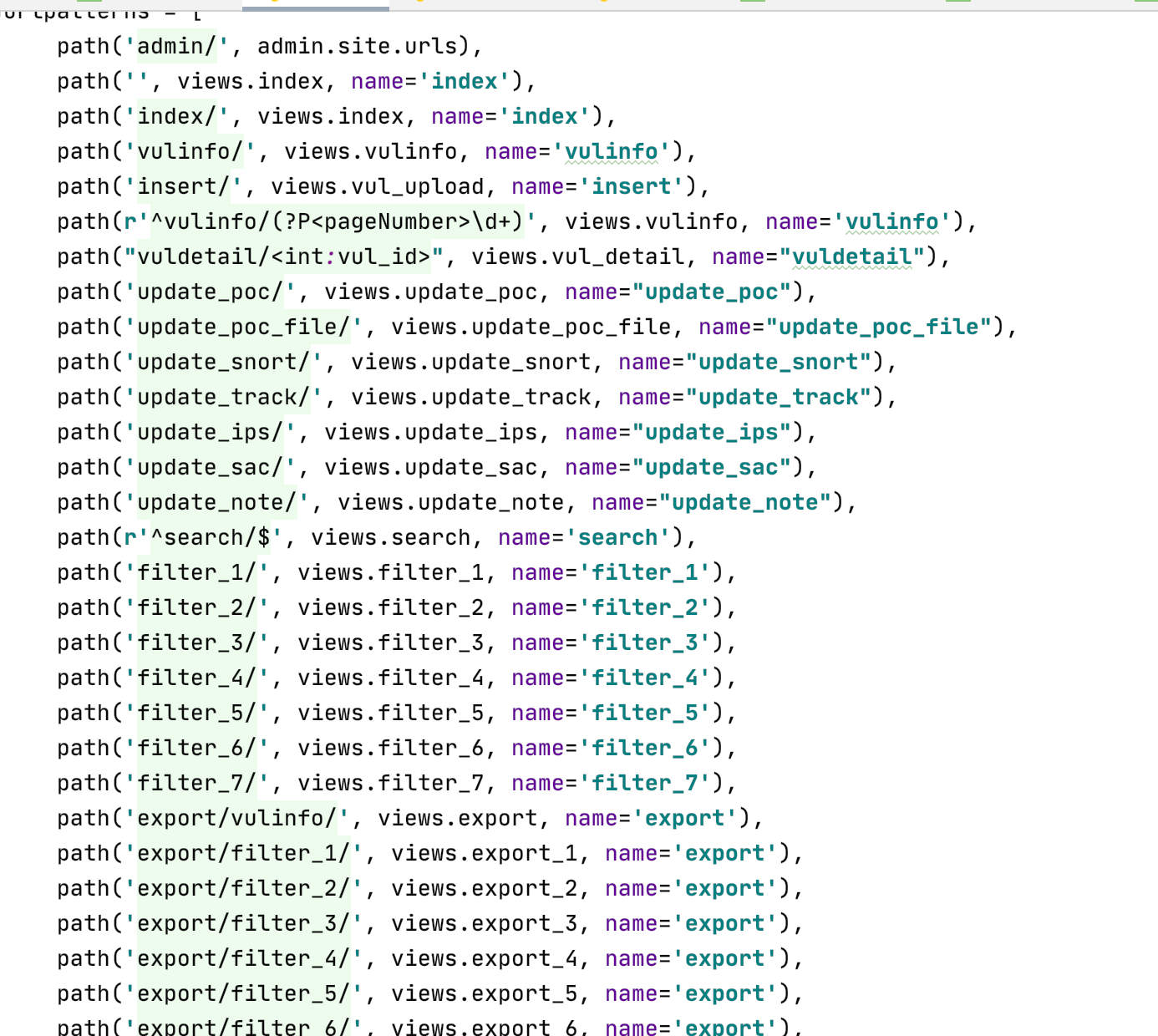
urls.py:
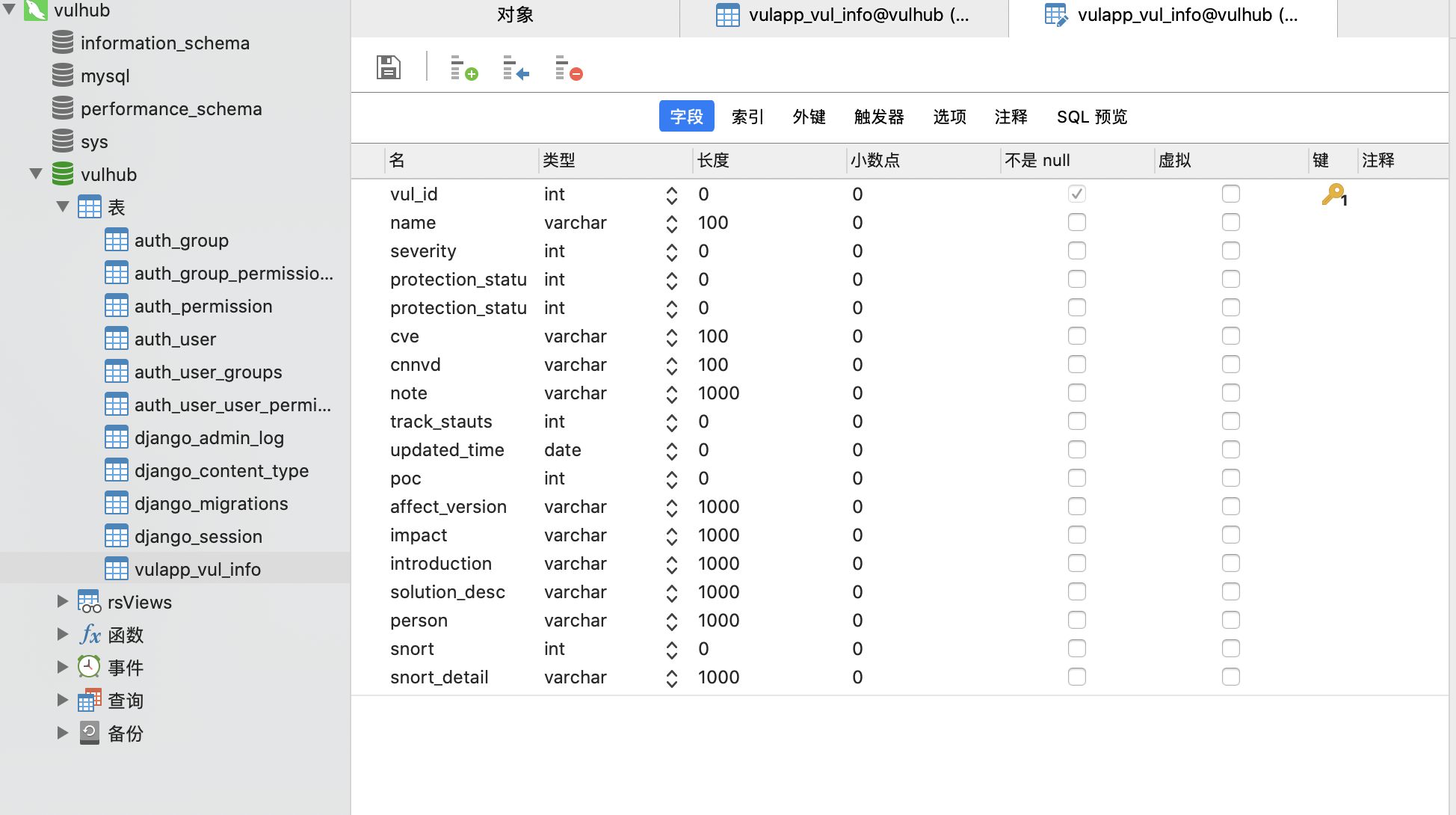
0x12 数据库设计:
在电脑上装好sql,使用navicat创建连接,在django项目中创建对于数据库并迁移
以下就是需要存到数据库中的信息字段:

在整体项目(和url文件在同一文件夹下)的settings中添加数据库的信息:

在项目命令行运行 python manage.py makemigrations和python manage.py migrate ,在navicat就能看到创建好的数据库
0x13 基础展示信息页面:(+分页)
在数据库中插入一些信息,然后想要在某个页面中以表格的形式展示它的部分内容
重点代码:data_sum = vul_info.objects.order_by('vul_id'),vul_info是model中的类名,order_by可以根据固定字段来进行排序
view.py中此功能完整代码:(加了分页的功能)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| @require_http_methods(["GET", ])
def vulinfo(request):
data_sum = vul_info.objects.order_by('vul_id')
paginator = Paginator(data_sum, 6) # 每页6条记录
page = request.GET.get('page', 1)
currentpage = int(page)
all_page_num = paginator.num_pages
try:
# 获取当前页码的记录
data_sum = paginator.page(page)
except PageNotAnInteger:
# 如果用户输入的页码不是整数时,显示第1页的内容
data_sum = paginator.page(1)
except EmptyPage:
# 如果用户输入的页数不在系统的页码列表中时,显示最后一页的内容
data_sum = paginator.page(paginator.num_pages)
info = {
"vuls": data_sum, # 定义了返回的数据名,在前端可以利用for循环来读取数据库里的内容
"currentpage": currentpage,
"all_page_num": all_page_num
}
return render(request, 'vulinfo.html', info) # vulinfo.html是前端页面的名字
|
urls.py:
1
| path(r'^vulinfo/(?P<pageNumber>\d+)', views.vulinfo, name='vulinfo')
|
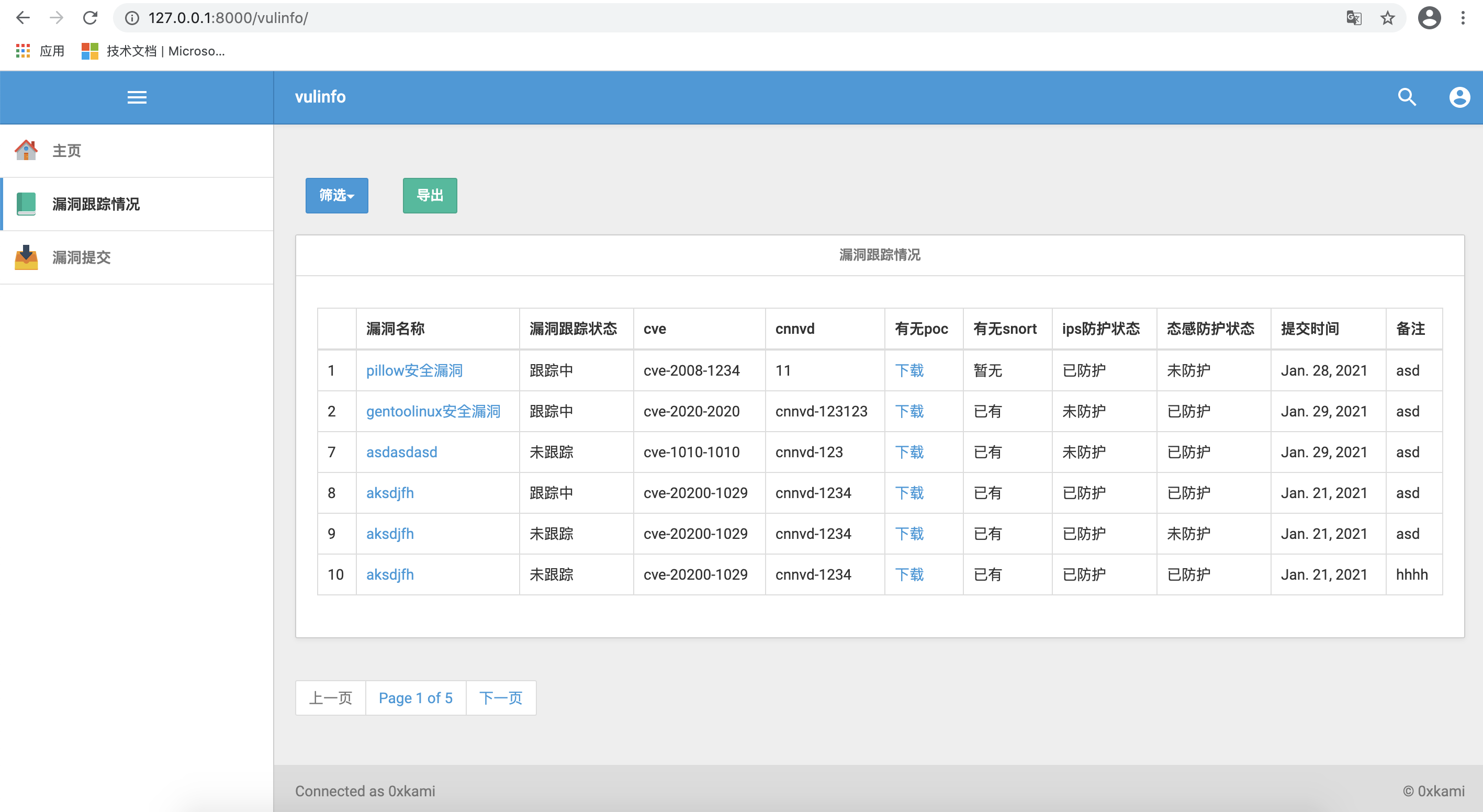
前端页面:
通过for循环,可以返回需要的数据,同时做了一个详细页面点击的链接
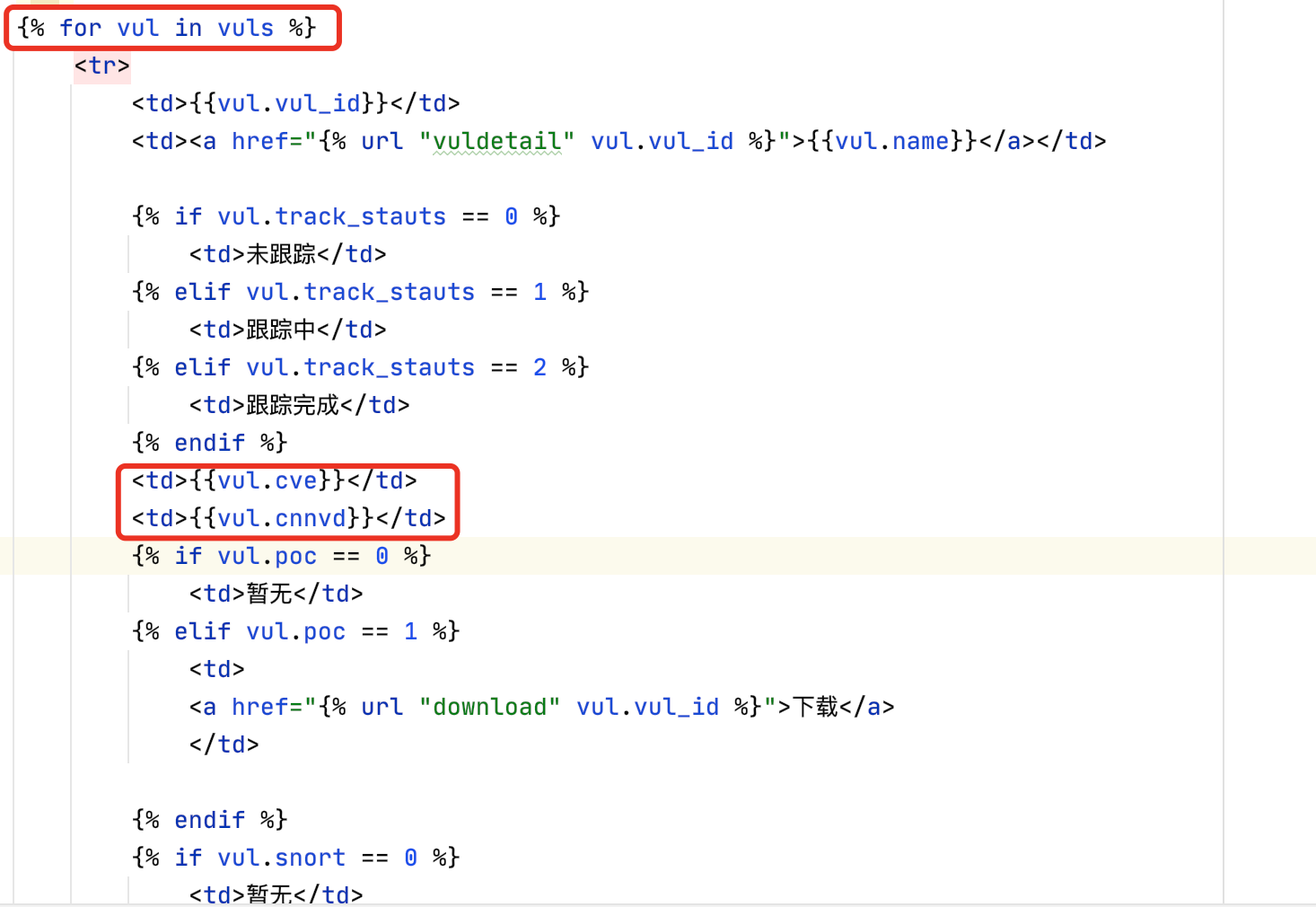
效果图如下:
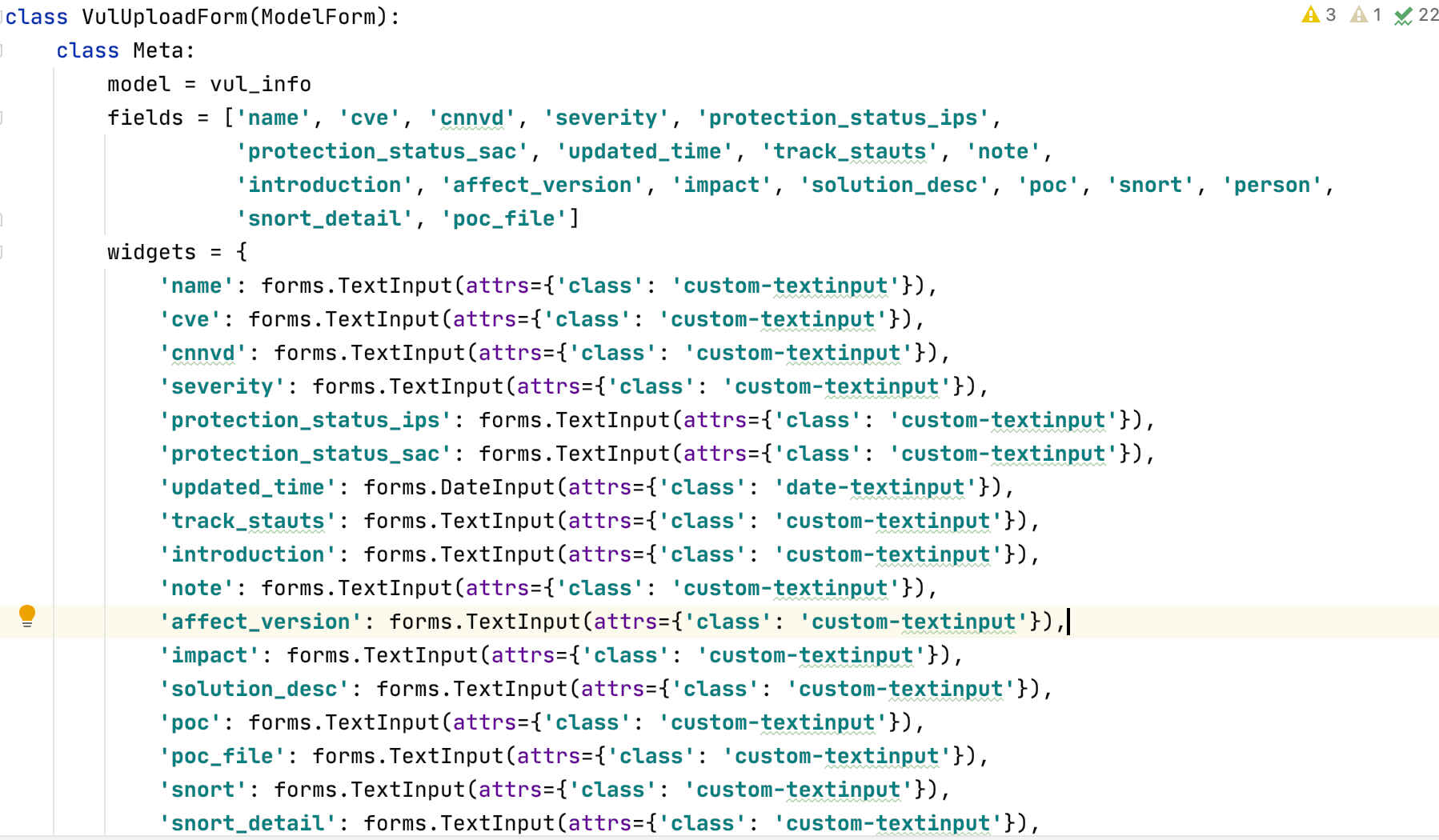
0x14 提交信息页面:(+上传文件)
使用forms进行信息的提交,在forms中进行定义:
view.py:(加了上传文件的功能)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @csrf_exempt
@require_http_methods(["GET", "POST"])
def vul_upload(request):
if request.method == "POST":
form = VulUploadForm(request.POST) # 获取form的内容
print(request.POST)
# 上传文件功能
file_obj = request.FILES.get("poc_file", None)
destination = open(os.path.join("#输入上传文件的地址", request.POST.get("poc_file")),'wb+')
for i in file_obj.chunks():
destination.write(i)
destination.close()
print(form)
if form.is_valid():
form.save()
return HttpResponse("新增成功")
content = {
"form": form
}
return render(request, "insert.html", content)
else:
return HttpResponse('Sorry...')
return render(request, 'insert.html')
|
效果图如下:
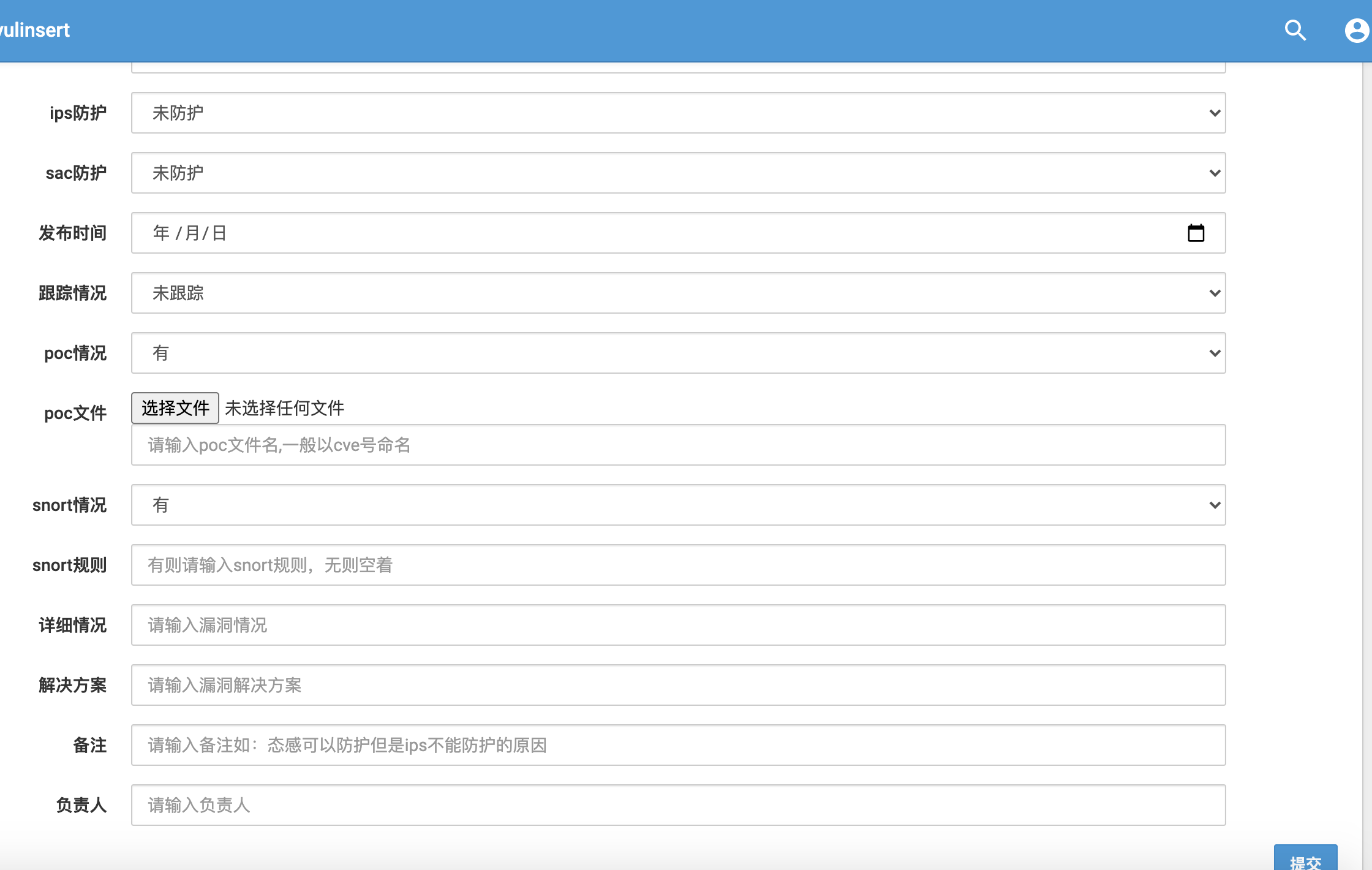
下拉框和日期选择实现:

0x15 详细信息页面:
展示所有数据库的数据,并对一部分数据提供修改的功能:
效果图如下:
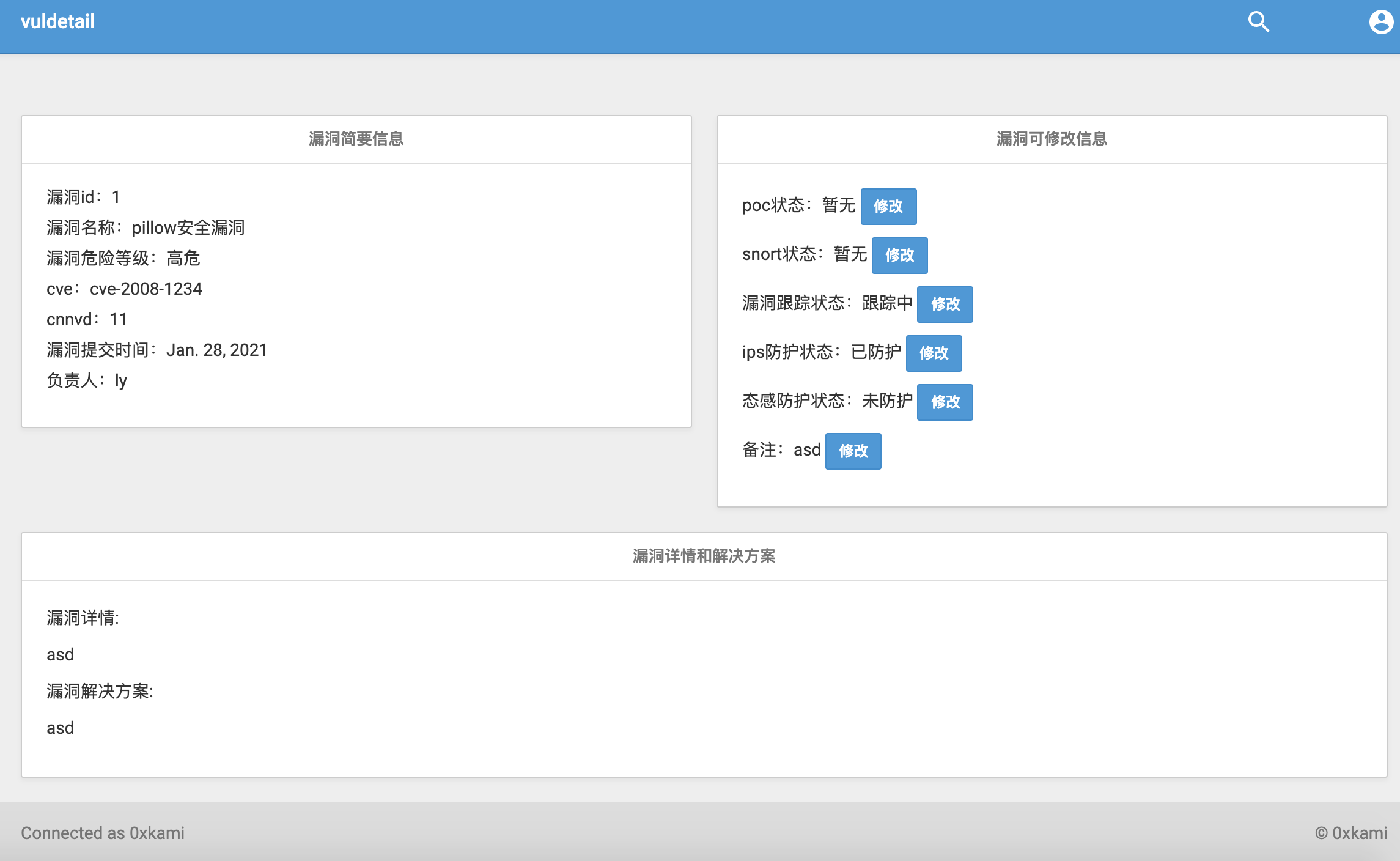
信息展示的前端同基础展示信息页面
修改功能使用了模态框+js
view.py:
通过js实现post,传输前端数据,获取对应的vul_id和要更新的数据
主要语句:vul_info.objects.filter(vul_id=xx).update(snort=xx)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def update_snort(request):
if request.method == "POST":
snort_info = request.POST.get('snort')
snort_detail = request.POST.get('snort_detail')
vulid = request.POST.get('vul_id')
vul_info.objects.filter(vul_id=vulid).update(snort=snort_info)
vul_info.objects.filter(vul_id=vulid).update(snort_detail=snort_detail)
return HttpResponse('save success!')
def update_track(request):
if request.method == "POST":
track_info = request.POST.get('track_stauts', '')
vulid = request.POST.get('vul_id')
print(vulid)
vul_info.objects.filter(vul_id=vulid).update(track_stauts=track_info)
return HttpResponse('save success!')
|
前端:
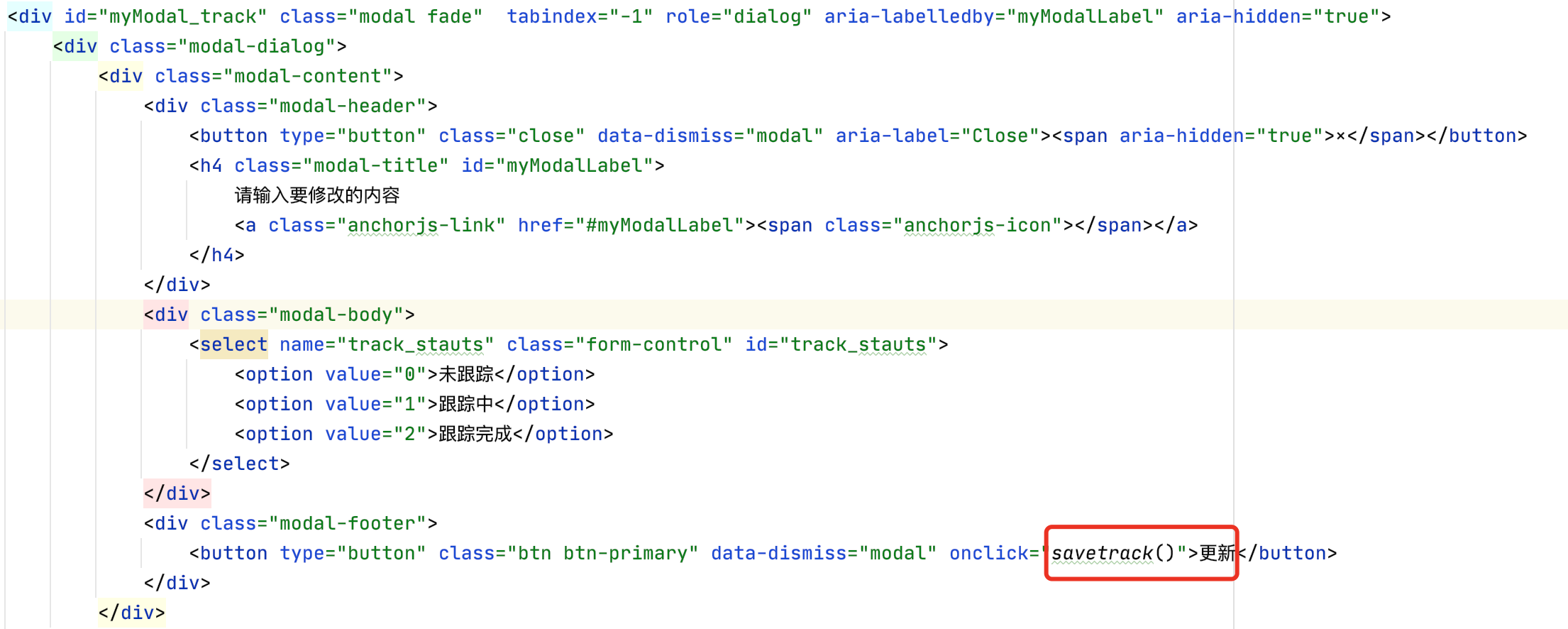
js:

效果图:
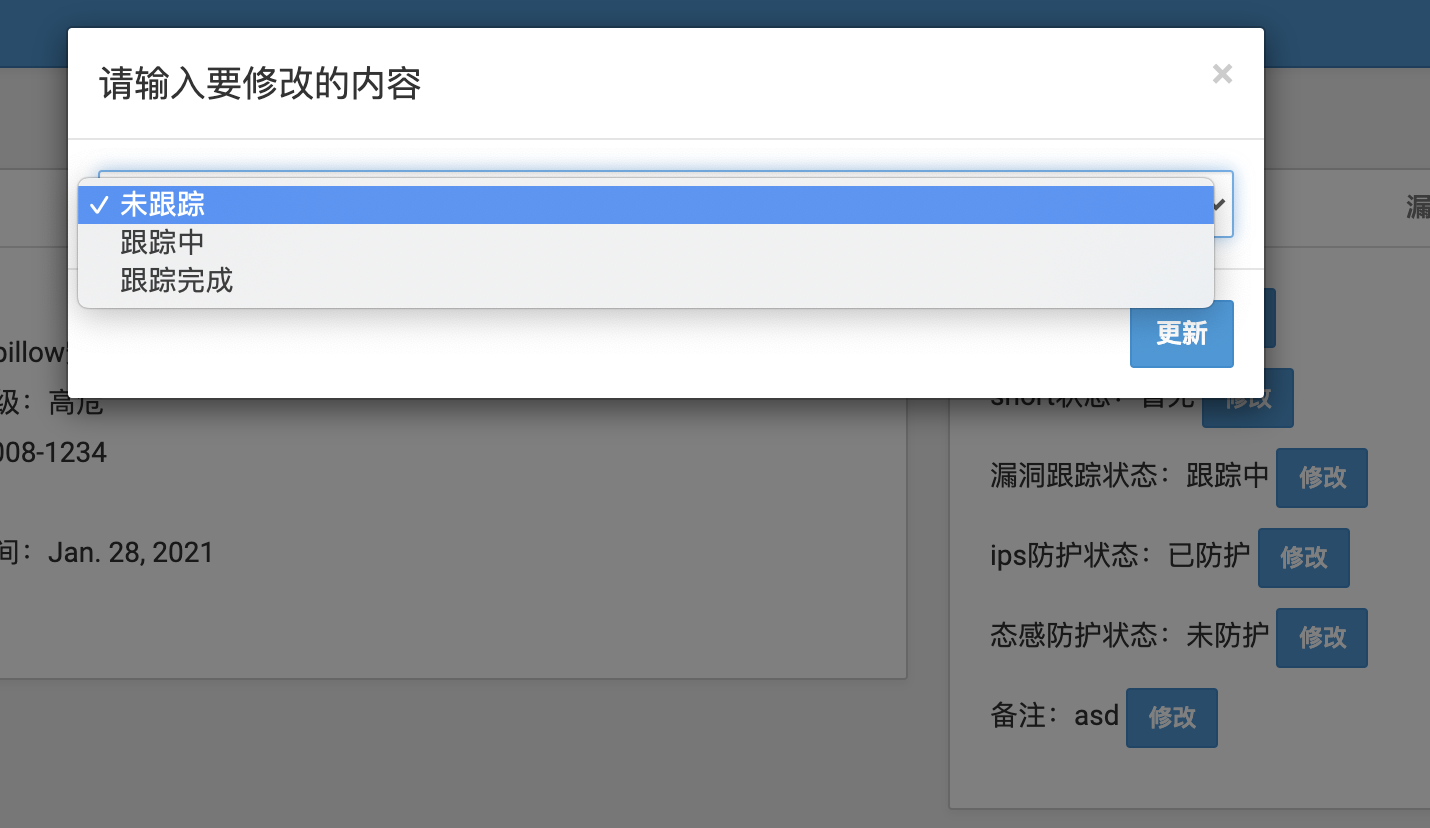
至此基础功能都已经实现
0x2 附加功能
0x21 搜索功能
使用q搜索,提供名字\cve\cnnvd的搜索
view.py:
1
2
3
4
5
6
7
| def search(request):
q = request.GET.get('q')
search_list = vul_info.objects.filter(Q(name__icontains=q) | Q(cve__icontains=q) | Q(cnnvd__icontains=q) )
error_msg = 'No result'
return render(request, 'vulinfo.html', {'vuls': search_list,
'error_msg': error_msg,
})
|
前端:
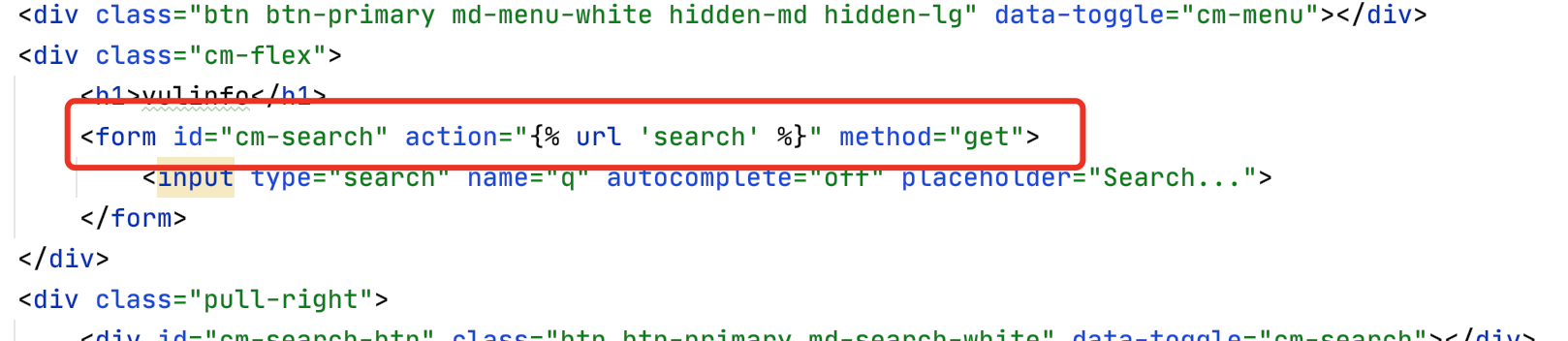
效果:
在这里输入关键字即可:
0x22 下拉框筛选显示
事先预定好了一些关键筛选,点击即可跳转对应的筛选页面:
筛选页面view.py:
1
2
3
4
5
6
| def filter_1(request):
search_lists = vul_info.objects.filter(Q(protection_status_ips=1) & Q(protection_status_sac=1))
error_msg = 'No result'
return render(request, 'vulinfo.html', {'vuls': search_lists,
'error_msg': error_msg,
})
|
前端:下拉框使用dropdown,点击后就会跳转

效果图:
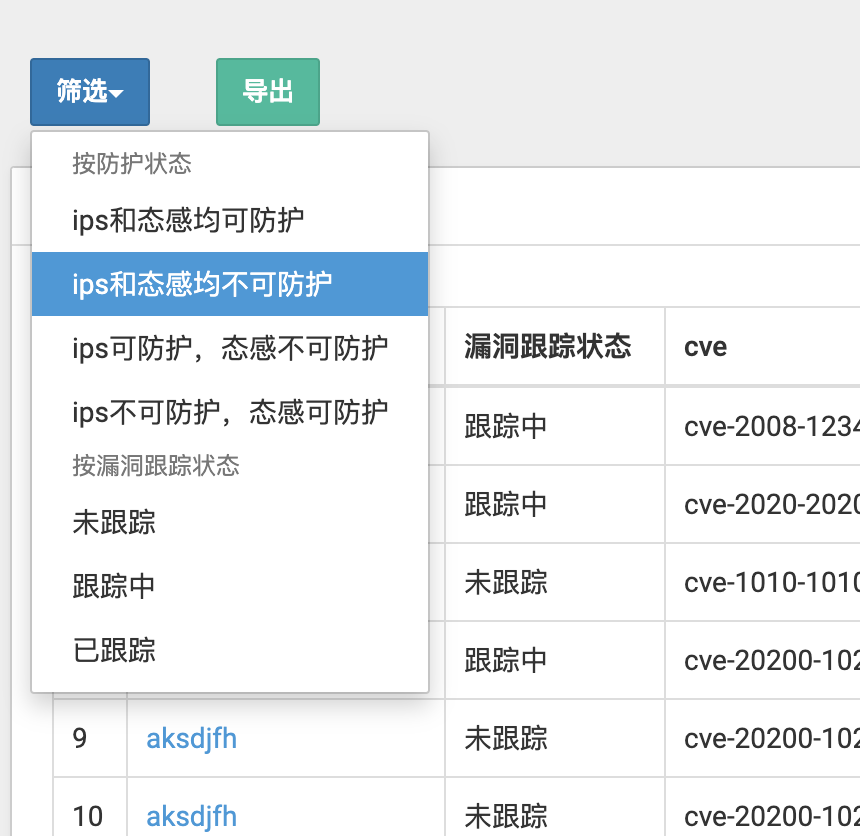
0x23 导出
前端写了一个导出按钮,点击即可输出为一个csv文件,支持不同筛选页面的输出
view.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def export(request):
vul_lis = vul_info.objects.all()
response = HttpResponse(content_type='text/csv')
time_now = time.strftime('%Y%m%d')
filename = 'vul_' + time_now
response.write(codecs.BOM_UTF8)
response['Content-Disposition'] = f'attachment; filename="{filename}.csv"'
writer = csv.writer(response)
writer.writerow(['vul_id', 'name', 'track', 'poc',
'snort', 'cve', 'cnnvd',
'ips', 'sac', 'note', 'update-time'])
for vul in vul_lis:
writer.writerow([vul.vul_id, vul.name, vul.track_stauts, vul.poc, vul.snort, vul.cve, vul.cnnvd,
vul.protection_status_ips, vul.protection_status_sac, vul.note, vul.updated_time])
return response
|
前端:

效果图:
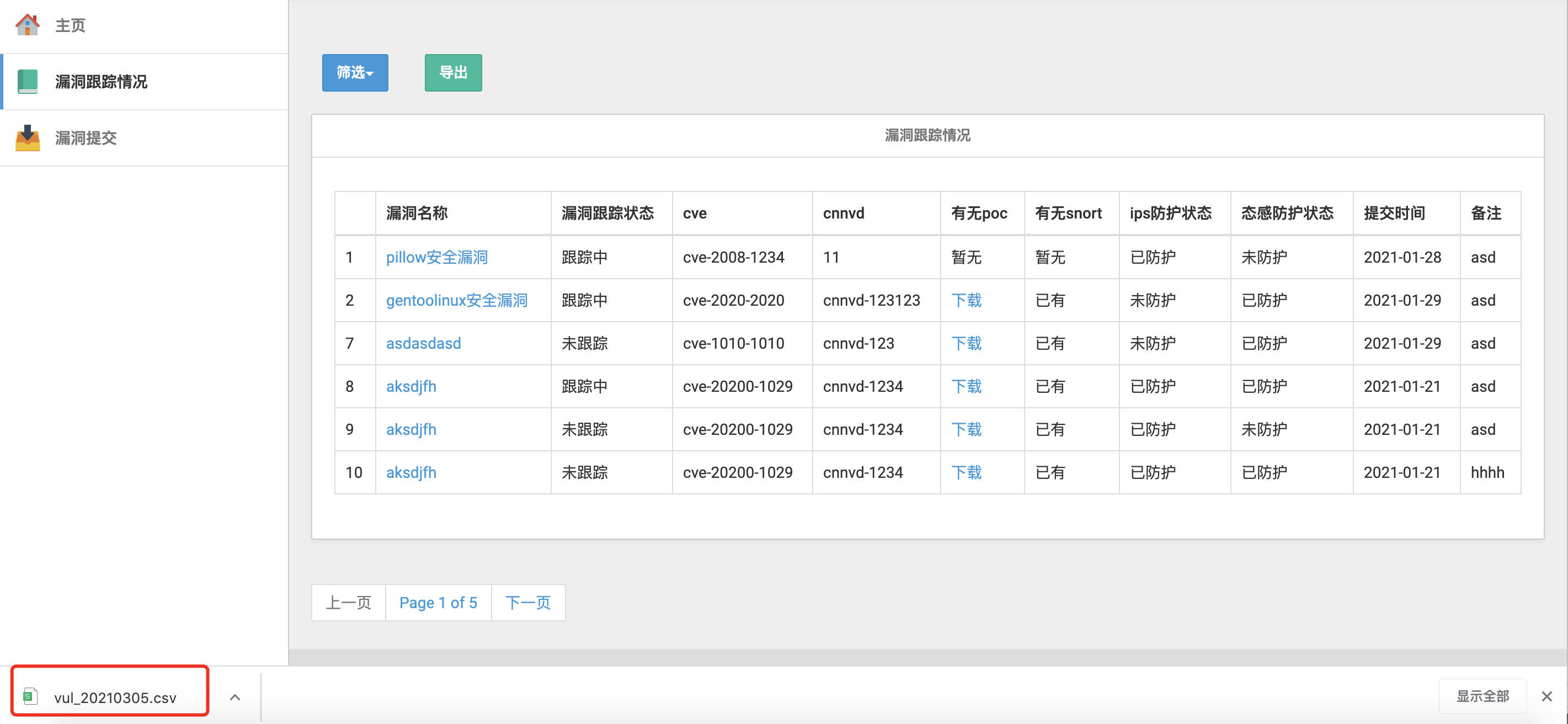
0x24 信息汇总页面
使用了c3表格,有模板
view.py:传输了一些数据到前端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| def index(request):
sum = vul_info.objects.all().count()
high = vul_info.objects.filter(severity='2').count()
med = vul_info.objects.filter(severity='1').count()
low = vul_info.objects.filter(severity='0').count()
wgzs = vul_info.objects.filter(track_stauts='0').count()
gzzs = vul_info.objects.filter(track_stauts='1').count()
ygzs = vul_info.objects.filter(track_stauts='2').count()
tgips = vul_info.objects.filter(Q(protection_status_ips=1) & Q(protection_status_sac=1)).count()
tg = vul_info.objects.filter(Q(protection_status_ips=0) & Q(protection_status_sac=1)).count()
ips = vul_info.objects.filter(Q(protection_status_ips=1) & Q(protection_status_sac=0)).count()
ntgips = vul_info.objects.filter(Q(protection_status_ips=0) & Q(protection_status_sac=0)).count()
d = int(tgips / sum * 100)
e = int(tg / sum * 100)
f = int(ips / sum * 100)
g = int(ntgips / sum * 100)
a = int(wgzs / sum * 100)
b = int(gzzs / sum * 100)
c = int(ygzs / sum * 100)
return render(request, 'index.html', {'sum': sum, 'high': high, 'med': med, 'low': low,
'wgz': a, 'gzz': b, 'ygz': c,
'wgzs': wgzs, 'gzzs': gzzs, 'ygzs': ygzs,
'tgips': d, 'tg': e, 'ips': f,'ntgips': g,
'tgipss': tgips, 'tgs': tg, 'ipss': ips,'ntgipss': ntgips})
|
效果图:
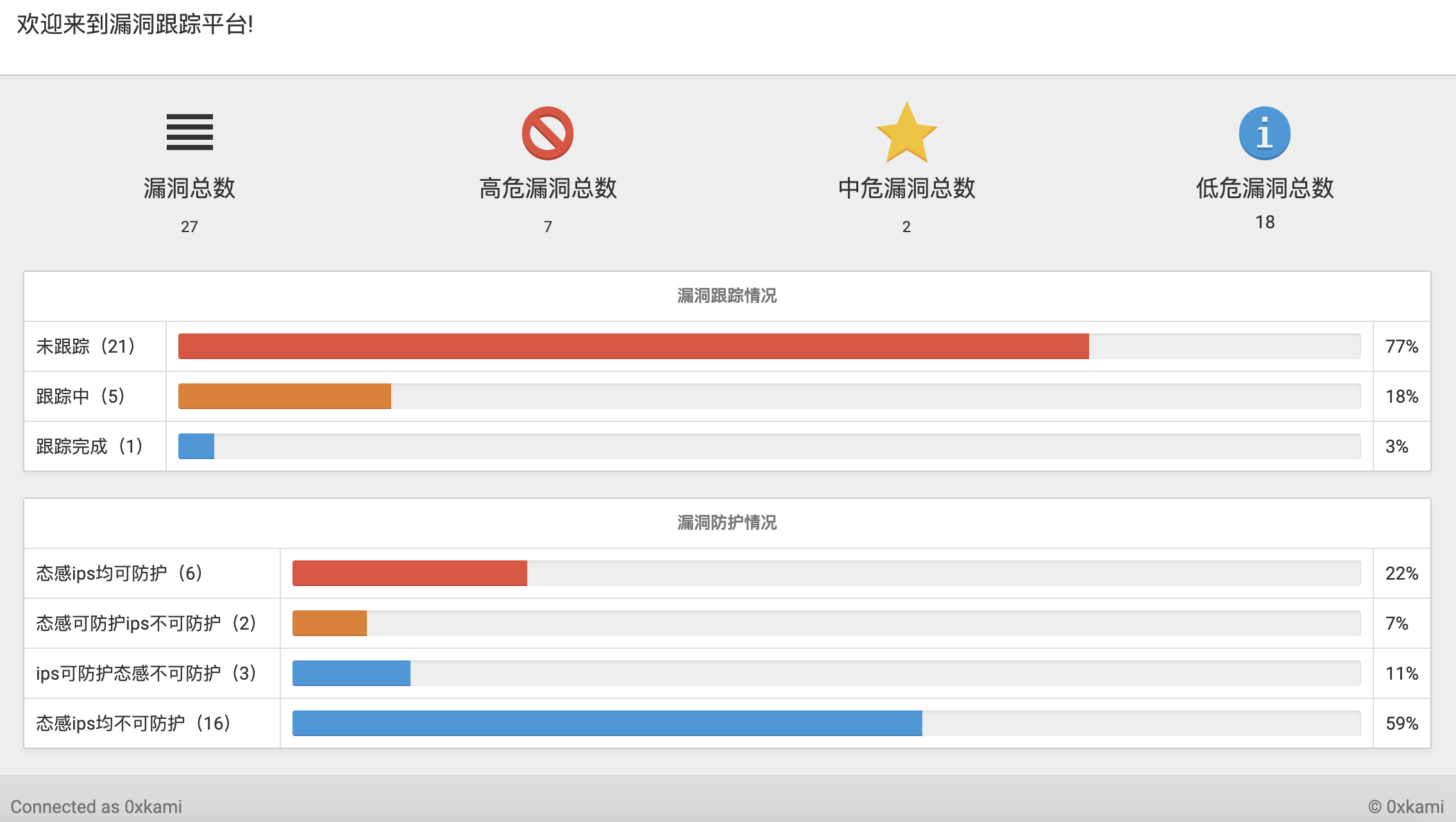
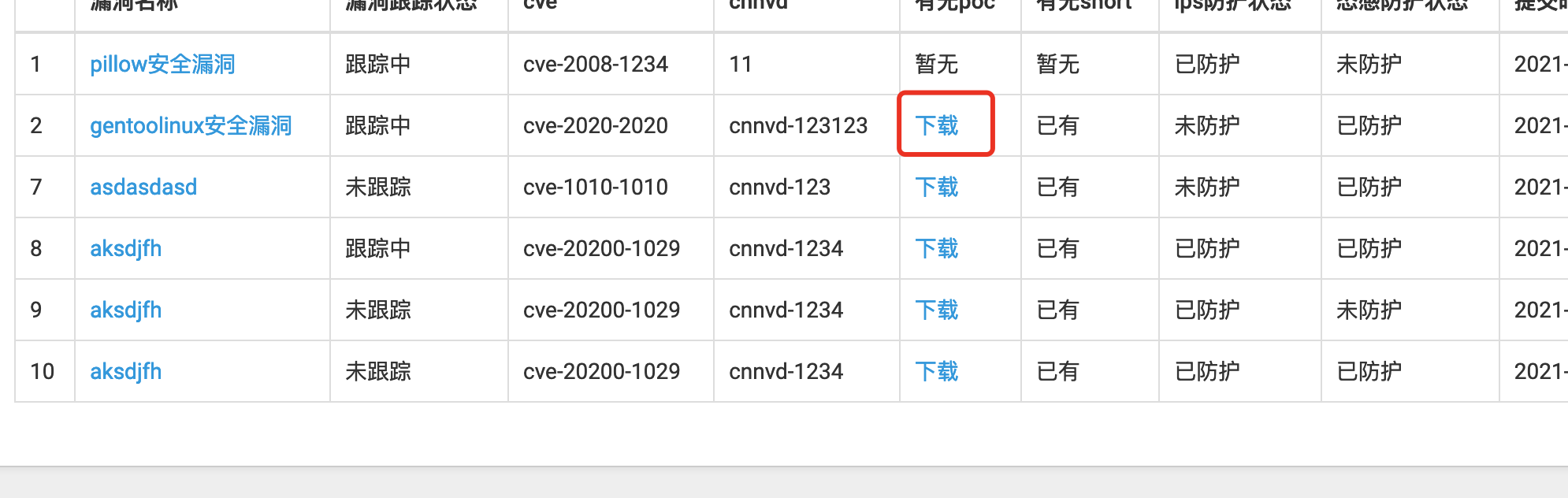
0x25 文件下载
单个poc文件下载功能,直接在页面上做了下载链接,点击即可下载对应poc:
view.py:
1
2
3
4
5
6
7
8
9
| def download_file(request, vul_id):
search_lists = vul_info.objects.get(vul_id=vul_id)
file_name = search_lists.poc_file
the_file_name = '#文件存储的地址'+ file_name
file = open(the_file_name, 'rb')
response = StreamingHttpResponse(file)
response['Content-Type'] = 'application/octet-stream'
response['Content-Disposition'] = 'attachement;filename="{0}"'.format(file_name)
return response
|
前端:

效果图: