在一次寻找大批量的久远漏洞的poc的时候,我这个python小白决定顺手写个exploit-db的爬虫
这类爬虫的项目其实还是有蛮多可以参考的
我的主要需求:已知cve号,搜索是否有poc并返回poc页面
先进行一次搜索流程
在输入框输入cve号,页面就会显示出链接
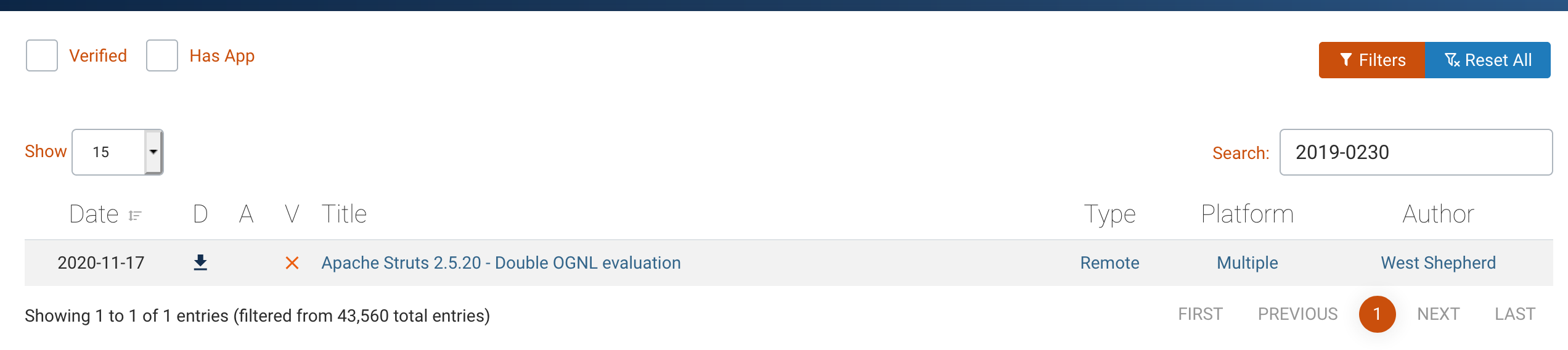
点击后,这个就是我们需要的poc的url:https://www.exploit-db.com/exploits/49068
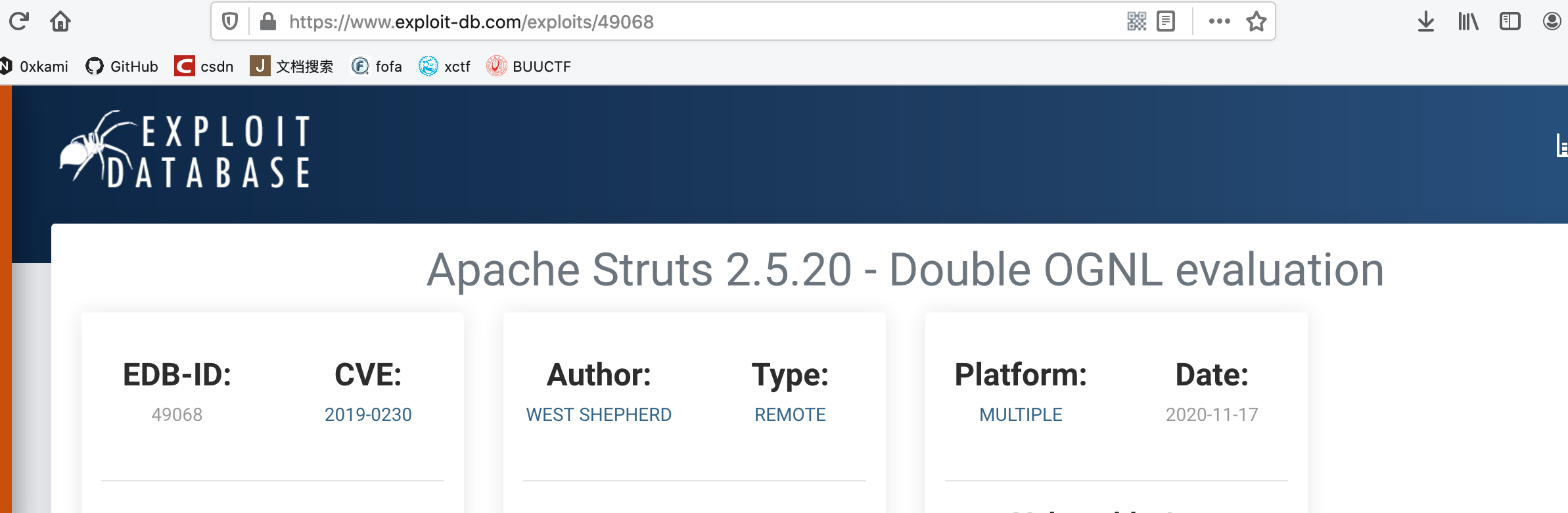
多尝试几个就可以知道poc的url就是”https://www.exploit-db.com/exploits/+某数字",那么这个某数字就是我们需要返回的
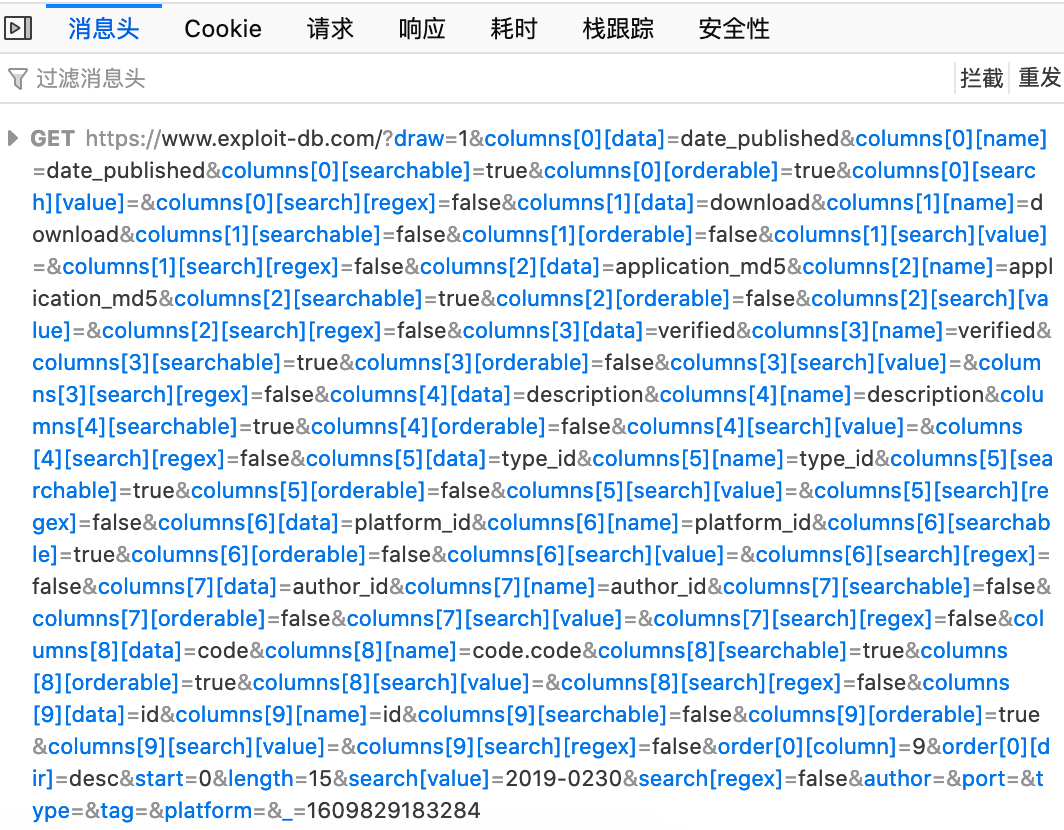
抓包,得到请求包,找到对应的cve号输入的位置search[value],修改为我们可以输入的参数
1 | url = 'https://www.exploit-db.com/?draw=2&columns[0][data]=date_published&columns[0][name]=date_published&columns[0][searchable]=true&columns[0][orderable]=true&columns[0][search][value]=&columns[0][search][regex]=false&columns[1][data]=download&columns[1][name]=download&columns[1][searchable]=false&columns[1][orderable]=false&columns[1][search][value]=&columns[1][search][regex]=false&columns[2][data]=application_md5&columns[2][name]=application_md5&columns[2][searchable]=true&columns[2][orderable]=false&columns[2][search][value]=&columns[2][search][regex]=false&columns[3][data]=verified&columns[3][name]=verified&columns[3][searchable]=true&columns[3][orderable]=false&columns[3][search][value]=&columns[3][search][regex]=false&columns[4][data]=description&columns[4][name]=description&columns[4][searchable]=true&columns[4][orderable]=false&columns[4][search][value]=&columns[4][search][regex]=false&columns[5][data]=type_id&columns[5][name]=type_id&columns[5][searchable]=true&columns[5][orderable]=false&columns[5][search][value]=&columns[5][search][regex]=false&columns[6][data]=platform_id&columns[6][name]=platform_id&columns[6][searchable]=true&columns[6][orderable]=false&columns[6][search][value]=&columns[6][search][regex]=false&columns[7][data]=author_id&columns[7][name]=author_id&columns[7][searchable]=false&columns[7][orderable]=false&columns[7][search][value]=&columns[7][search][regex]=false&columns[8][data]=code&columns[8][name]=code.code&columns[8][searchable]=true&columns[8][orderable]=true&columns[8][search][value]=&columns[8][search][regex]=false&columns[9][data]=id&columns[9][name]=id&columns[9][searchable]=false&columns[9][orderable]=true&columns[9][search][value]=&columns[9][search][regex]=false&order[0][column]=9&order[0][dir]=desc&start=0&length=15&search[value]=%s&search[regex]=false&author=&port=&type=&tag=&platform=&_=1606893892234'%s |
刚开始直接获取的是返回的页面的html,但是没有相关数字的信息,一度以为自己写错了,毕竟这算是我第二次写爬虫。后来查看页面源代码,确实没有相关的信息,跑去问gps(前端,才知道是拿了接口返回的数据,塞到网页里
f12后发现在json数据包里
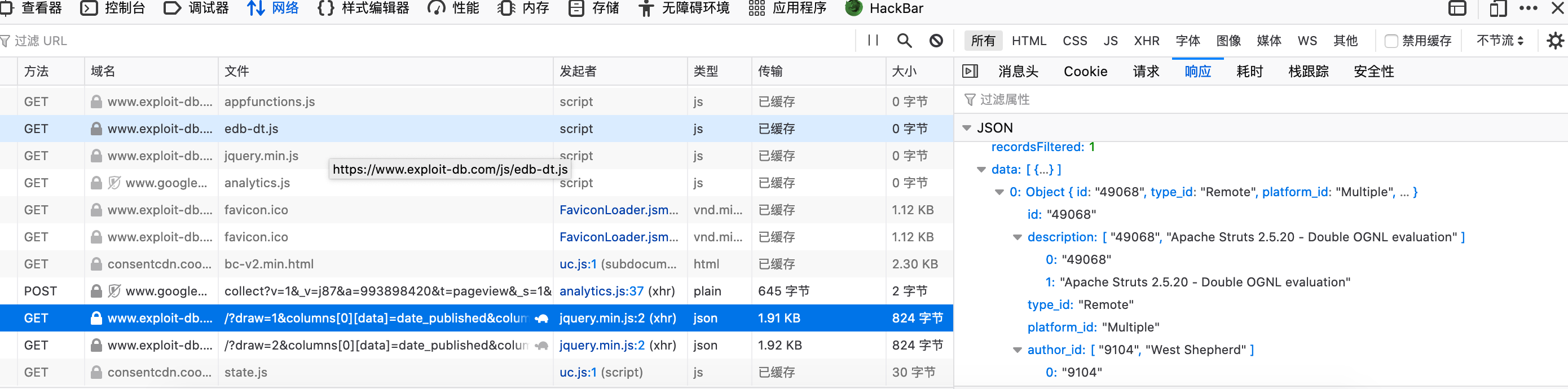
于是开始研究怎么获取json包的数据
重点函数:spider_request.json()
但是一开始使用这个函数一直报错,提示没有返回json,确认了下请求头也没有错误
改了很久,最后将header改为这样就可以了
1 | header = { |
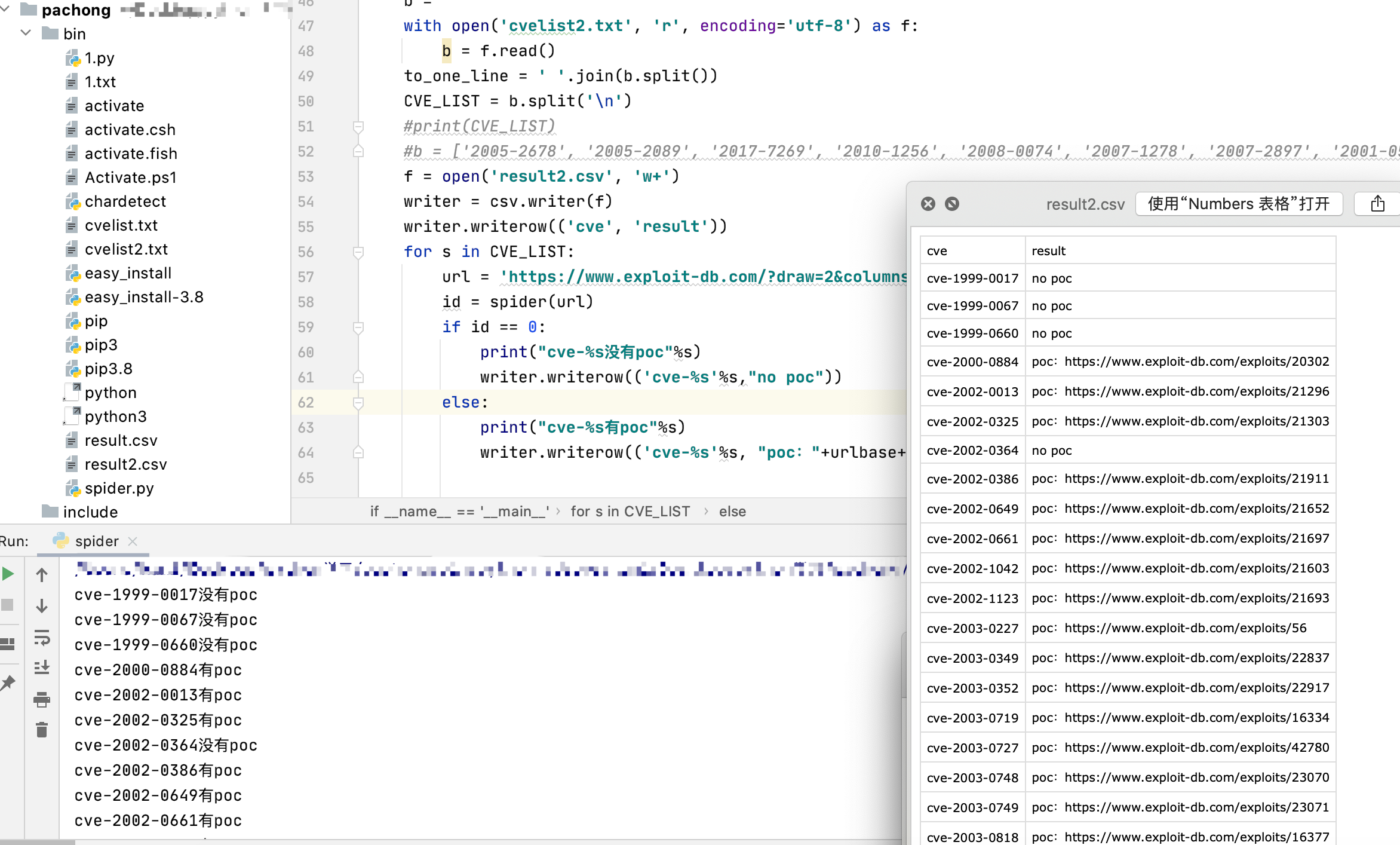
运行效果: